

系列文章目录
【计算机组织与体系结构】实验一:算术逻辑单元的实现
【计算机组织与体系结构】实验二:给定指令系统的处理器设计
【计算机组织与体系结构】实验三:流水线处理器
【计算机组织与体系结构】实验四:指令 CACHE 的设计与实现
文章目录
一、实验目的
- 掌握 Vivado 集成开发环境
- 掌握 Verilog 语言
- 掌握 FPGA 编程方法及硬件调试手段
- 深刻理解指令 Cache 的结构和整体工作原理
二、实验环境
Vivado 集成开发环境
三、实验内容
根据课程第八章所讲的存储系统的相关知识,自行设计一个指令 cache,并使用 Verilog 语言实现之。要求设计的指令 Cache 可以是 2 路或 4 路,每路 128 行,每行 32 字节,最终实现的 cache 能够通过所提供的自动测试环境。
1、指令 Cache 各模块及工作过程的介绍
指令 Cache 介于 CPU 和主存之间。其使用类 Sram 接口与 CPU 进行通信,当 CPU 需要使用数据时,将 Cache内缓存的数据发送给 CPU;使用 AXI 接口与主存进行通信,当Cache 发生不命中时,将主存中的数据替换到Cache 的数据块内。因此,要实现一个指令 Cache ,一方面我们需要知道其内部的构成(在本节中将会详细阐述),另一方面我们需要知道 Cache 和 CPU 以及 AXI 总线是如何相互配合工作的(在后两节实现类 Sram协议和实现 AXI 协议中会详细阐述)
如下图所示,一个简单的指令 Cache 内部分主要由两级流水段和控制模块构成,本次实验已经提供了目录表tagv_ram 以及数据块 data_ram 的实现,同学们主要需要在已给的 Cache 代码框架(见文件./cache.v)中实现第一级流水的请求缓存 request_buffer 以及控制模块部分。当然,对于学有余力的同学可以尝试自己实现设计并实现 Cache 主模块、目录表和数据块。

接下来,我们将具体介绍 Cache 两级流水段和控制模块的工作原理和实现。
两级流水段
指令 Cache 支持两级流水段的流水访存。两级流水段为地址流水段和数据流水段,分别与 CPU 的地址握手阶段和数据握手阶段相配合。Cache 在地址流水段从 CPU 接收并存储访存地址,在数据流水段查找并返回数
据。
对于地址流水段,主要模块是一个请求缓存 request_buffer ,其由多个用于缓存访存地址等信息的寄存器构成。在 CPU 将 cpu_req 拉高且 Cache 未阻塞时,请求缓存会解析出访存地址的 tag、index、offset 等信息。其中,index 和 tag 会被送到下一级流水段中的目录表(图中 Tagv Ram )中,index 和 offset 会被送到下一级流水段中的数据块中(图中 Data Ram )中。
请求缓存将这些信息以及访存地址缓存到寄存器中,同时将原本的访存地址缓存在一个额外的寄存器ll_address 中。其之所以要缓存上上次的访存地址,是因为此时 Cache 刚刚判断出上上次的访存是否命中,若未命中则需要利用 ll_address 中缓存的上上次访存地址向内存中读取数据。
Note: 关于地址的解析,由于本实验要求的 Cache 每路为 128 行,因此 index 需要 7 位,即 2^7 = 128;每行由 8 个块构成,每个块 32 位(4 个字节),因此 offset 需要 5 位,即 2^5 = 8 * 4;地址其余 20 位作为 tag 。

对于数据流水段,主要有两个模块,分别为目录表和数据块。这两个模块均已给出 verilog 实现示例,同学们可以直接使用或根据自己的设计进行适当修改,也可以尝试自己实现。
目录表用于存储缓存数据内存地址的 tag ,当 CPU 发起访存请求时,Cache 通过到目录表查找访存地址的 tag来判断缓存是否命中。根据本实验要求,Cache 每路共有 128 行,每行一个 tag ,故每路目录表需要维护一个128 * 20 bit 的 tag 数组,同时,每行还需要额外一位有效位来标记该行是否有缓存数据,故每路目录表需要维护一个 128 * (20+1) bit 大小的数组。此外,目录表还需要支持写入,在 Cache 未命中从内存读取访存数据时,需要对目录表进行更新。以下给出一个使用 Verilog 实现的二路 Cache 的目录表示例供大家参考。
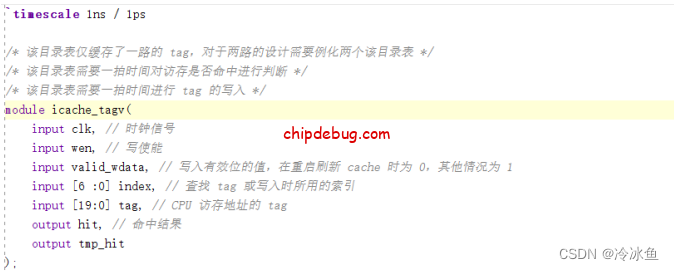
/* 该目录表仅缓存了一路的 tag,对于两路的设计需要例化两个该目录表 */
/* 该目录表需要一拍时间对访存是否命中进行判断 */
/* 该目录表需要一拍时间进行 tag 的写入 */
module icache_tagv(
input clk, // 时钟信号
input wen, // 写使能
input valid_wdata, // 写入有效位的值,在重启刷新 cache 时为 0,其他情况为 1
input [6 :0] index, // 查找 tag 或写入时所用的索引
input [19:0] tag, // CPU 访存地址的 tag
output hit // 命中结果
);
/* --------TagV Ram------- */
// | tag | valid |
// |20 1|0 0|
reg [20:0] tagv_ram[127:0];
/* --------Write-------- */
always @(posedge clk) begin
if (wen) begin
tagv_ram[index] <= {tag, valid_wdata};
end
end
/* --------Read-------- */
reg [20:0] reg_tagv;
reg [19:0] reg_tag;
always @(posedge clk) begin
reg_tagv = tagv_ram[index];
reg_tag = tag;
end
assign hit = (reg_tag == reg_tagv[20:1]) && reg_tagv[0];
endmodule
数据块中则真正缓存了数据,其根据 index 查找到对应的 Cache 行,根据 offset 最终确定访问的数据。根据本实验要求,Cache 每路共有 128 行,每行 32 字节,故每路数据块大小为 128 * 32 B 。由于数据块较大,建议使用 Vivado 提供的 block memory generator 自动生成 ram ip 核来实现。
以实现上述一路数据块为例,生成 ip 核步骤如下:




最后给出一个使用 Verilog 实现的二路 Cache 的数据块示例供大家参考。
Note: 在使用数据块实例模块时,需要根据上文在实验项目中添加 ram ip 核,但在设置 read width 和write width 时需要改为 32 而非 256 。
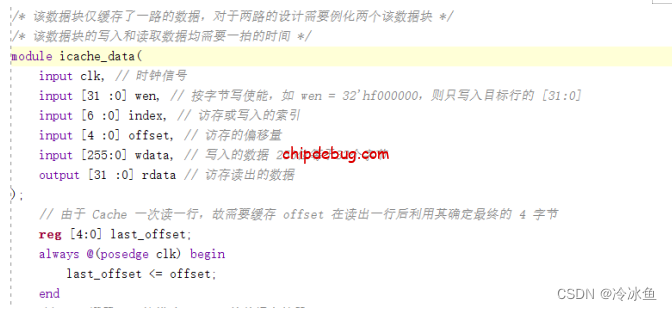
/* 该数据块仅缓存了一路的数据,对于两路的设计需要例化两个该数据块 */
/* 该数据块的写入和读取数据均需要一拍的时间 */
module icache_data(
input clk, // 时钟信号
input [31 :0] wen, // 按字节写使能,如 wen = 32'hf000000,则只写入目标行的 [31:0]
input [6 :0] index, // 访存或写入的索引
input [4 :0] offset, // 访存的偏移量
input [255:0] wdata, // 写入的数据
output [31 :0] rdata // 访存读出的数据
);
// 由于 Cache 一次读一行,故需要缓存 offset 在读出一行后利用其确定最终的 4 字节
reg [4:0] last_offset;
always @(posedge clk) begin
last_offset <= offset;
end
//-----调用 IP 核搭建 Cache 的数据存储器-----
wire [31:0] bank_douta [7:0];
/*
Cache_Data_RAM: 128 行,每行 32bit,共 8 个 ram
接口信号含义: clka:时钟信号
ena: 使能信号,控制整个 ip 核是否工作
wea:按字节写使能信号,每次写 4 字节,故 wea 有 4 位
addra:地址信号,说明读/写的地址
dina:需要写入的数据,仅在 wea == 1 时有效
douta:读取的数据,在 wea == 0 时有效,从地址 addra 处读取出数据
*/
generate
genvar i;
for (i = 0 ; i < 8 ; i = i + 1) begin
inst_ram BANK(
.clka(clk),
.ena(1'b1),
.wea(wen[i*4+3:i*4]),
.addra(index),
.dina(wdata[i*32+31:i*32]),
.douta(bank_douta[7-i])
);
end
endgenerate
assign rdata = bank_douta[last_offset[`ICACHE_OFFSET_WIDTH-1:2]];
endmodule
Note: 对于指令 Cache 数据块的写入仅在 Cache 未命中从内存读取数据时才会发生,由于本实验中 AXI 总线单次仅返回 4 字节,故每次对于数据块也只写入 4 字节,这里给出一个简单的示例说明如何使用 icache_data模块实现特定 4 字节的写入。
该模块涉及写入的接口为 wen、index、wdata,若需要写入的数据 index = 7’h00, offset = 5’h04,data = 32’h12345678,则对接口赋值 wen = 32’h0f000000, index = 7’h00, wdata ={8{data}}。其中对于 wen ,由于偏移量为 4 字节,即需要写入的是该行的第二个数据,故将 wen[27:24] 置高,其余置低,以示仅将 wdata 的 [32:63] 写入到目标行的 [32:63] (wen 的每 4 位对应 Cache 行的 4 字节)。
当然,两段仅是在 Cache 命中的情况下,若出现未命中的情况,则通过 AXI 总线访存,这是需要耗费多个周期,耗费的周期数与 Cache 自动机在未命中时的状态转移设计以及 AXI 访存机制相关。对于未命中情况的处理,将在控制模块的实现中提供实现方案。
控制模块
控制模块主要包含 LRU 模块以及状态自动机模块。
LRU 即最近最少使用,LRU 模块用于 Cache 未命中时对缓存块的替换,其只有一个输出 sel_way,用于告知目录表和数据块需要更换哪一路的数据。
该模块需要维护一个 lru 表,该表记录了最近每行各路的使用情况,在选择替换块时,只需根据该数组找到目标行中最近最少使用的一路进行替换即可。以二路 Cache 为例,该 lru 表只需记录每行上次使用的路的编号即可,则在替换时选择另一路即可,由此可知二路 Cache 的 lru 表每行只需 1 bit,共需 128*1 bit 。此外,lru表在每次 CPU 访存命中以及未命中进行 Cache 更新时,都需要进行更新。
状态自动机模块用于标识当前 Cache 的工作状态,便于发出相应的控制信号,控制整个 Cache 的运行状态。
以下是一个指令 Cache 的 DFA 状态转移示意图,同学们可以将该 DFA 应用到自己的 Cache 中,也可以自行设计 DFA。
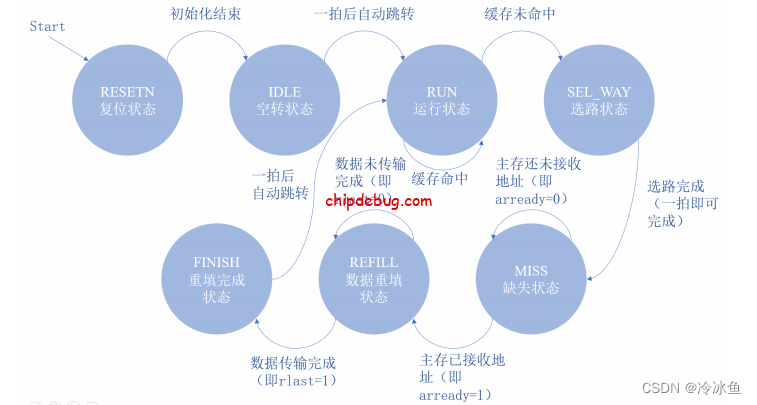
其中各个状态的详细说明如下。

在利用 Verilog 实现时,可以将这 7 个状态分别映射为数字 0-6,并利用一个寄存器 state 记录当前 Cache 的状态,且每一拍都需要根据给出的自动机规则更新 state。在实现其他模块时,通常需要先确定当前 Cache的状态,此时只需访问 state。以下给出一个代码框架供同学们参考。
parameter idle = 0;
parameter run = 1;
parameter sel_way = 2;
parameter miss = 3;
parameter refill = 4;
parameter finish = 5;
parameter resetn = 6;
reg [2:0] state;
/* DFA */
always @(posedge clk) begin
if (!rst) begin
state <= idle;
end
else begin
/*TODO:根据设计的自动机的状态转移规则进行实现 */
end
end
/* 某功能模块 */
always @(posedge clk) begin
if (!rst) begin
/*TODO:初始化相关寄存器 */
end
else begin
if (state == idle) begin
/*TODO:该模块在 idle 状态下的行为 */
end
else if (state == run) begin
/*TODO:该模块在 run 状态下的行为 */
end
...
end
end
2、实现类 Sram 协议
给出本次实验中,同学们设计的指令 Cache 与 CPU 连接的接口:
module cache (
input clk , // clock, 100MHz
input rst , // active low
// Sram-Like 接口信号定义:
// 1. cpu_req 标识 CPU 向 Cache 发起访存请求的信号,当 CPU 需要从 Cache 读取数据时,该信号置为 1
// 2. cpu_addr CPU 需要读取的数据在存储器中的地址, 即访存地址
// 3. cache_rdata 从 Cache 中读取的数据,由 Cache 向 CPU 返回
// 4. addr_ok 标识 Cache 和 CPU 地址握手成功的信号,值为 1 表明 Cache 成功接收 CPU 发送的地址
// 5. data_ok 标识 Cache 和 CPU 完成数据传送的信号,值为 1 表明 CPU 在本时钟周期内完成数据接收
input cpu_req , //由 CPU 发送至 Cache
input [31:0] cpu_addr , //由 CPU 发送至 Cache
output [31:0] cache_rdata , //由 Cache 返回给 CPU
output cache_addr_ok, //由 Cache 返回给 CPU
output cache_data_ok, //由 Cache 返回给 CPU
...
);
/*TODO:完成指令 Cache 的设计代码 */
endmodule
接下来通过指令 Cache 与 CPU 在工作中的交互过程,具体解释以上给出的各个接口的具体作用。
通常指令 Cache 在流水线中占用两拍(cache 命中的情况下),如下图所示(cpu_ 前缀的信号由 CPU 发给Cache ,cache_ 前缀的信号由 cache 发给 CPU )。
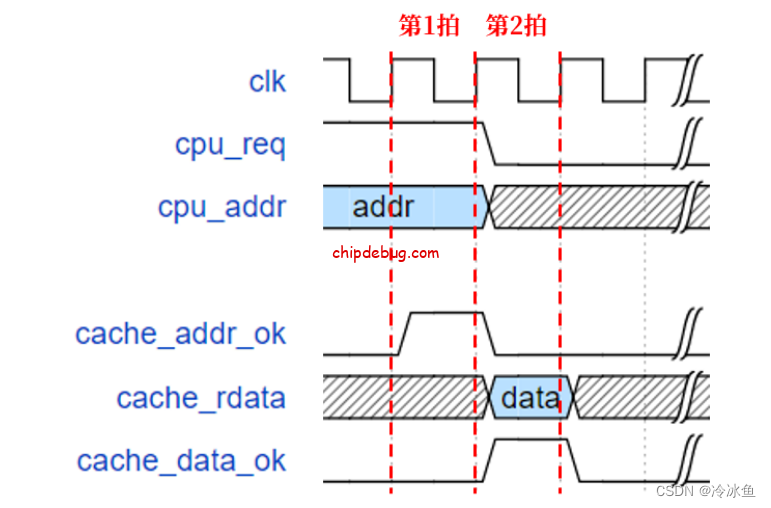
第一拍:CPU 在这一拍之前拉高读请求信号 cpu_req 并给出读地址 cpu_addr。Cache 拉高cache_addr_ok 表示 Cache 已经接收读地址,Cache 和 CPU 地址握手成功。
第二拍:若 Cache 命中,则 Cache 在第二拍返回给 CPU 读出的数据/指令 cache_rdata,同时拉高 cache_data_ok 使 CPU 读取指令,至此 Cache 和 CPU 完成数据传送。注意,返回一条指令则cache_data_ok 只能拉高一拍,该信号拉高 X 拍表示返回 X 条指令。
3、实现 AXI 协议
给出本次实验中,同学们设计的指令 Cache 与 AXI 总线连接的接口:
module cache (
input clk , // clock, 100MHz
input rst , // active low
// Sram-Like 接口信号定义:
...
// AXI 接口信号定义:
// Cache 与 AXI 的数据交换分为两个阶段:地址握手阶段和数据握手阶段
output [3 :0] arid , //Cache 向主存发起读请求时使用的 AXI 信道的 id 号,设
置为 0 即可
output [31:0] araddr , //Cache 向主存发起读请求时所使用的地址
output arvalid, //Cache 向主存发起读请求的请求信号
input arready, //读请求能否被接收的握手信号
input [3 :0] rid , //主存向 Cache 返回数据时使用的 AXI 信道的 id 号,设
置为 0 即可
input [31:0] rdata , //主存向 Cache 返回的数据
input rlast , //是否是主存向 Cache 返回的最后一个数据
input rvalid , //主存向 Cache 返回数据时的数据有效信号
output rready //标识当前的 Cache 已经准备好可以接收主存返回的数据
);
/*TODO:完成指令 Cache 的设计代码 */
endmodule
指令 Cache 与 AXI 的数据交换分为两个阶段:地址握手阶段和数据握手阶段。
在地址握手阶段,如下图所示,Cache 给出使用的 AXI 信道的 id 号和目标地址,同时拉高 arvalid 以示发起读请求。arready 拉高时说明此时总线可以接收读请求。当 arvalid 和 arready 同时拉高则说明地址握手阶段完成。
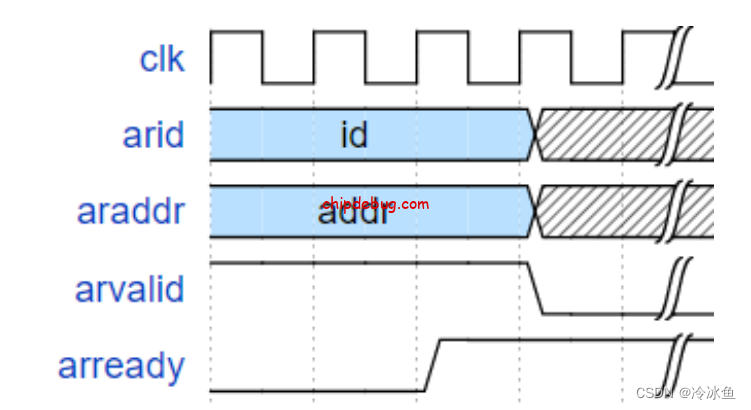
在数据握手阶段,如下图所示,主存给出使用的 AXI 信道的 id 号和目标数据,同时拉高 rvalid 以示返回数据有效,请求方(即 Cache )可以读取该数据。当主存返回最后 4 字节时,会拉高 rlast 以示这是最后一次数据传输。rready 拉高时说明 Cache 可以接收主存返回的数据。

本次实验只涉及 AXI 协议的部分内容,感兴趣想要详细了解 AXI 协议的同学可以下载AMBA® AXI Protocol自行阅读。
四、实验要求
根据实验内容中的描述实现一个指令 Cache 。对于目录表和数据块的实现,可以采用指导书的参考示例,也可以自行实现;对于 Cache 主模块的实现,可以使用实验环境中提供的代码框架(即./cache.v 文件,该
文件未添加到 Vivado 项目中),也可以完全自行设计实现 Cache 主模块,但是必须确保 Cache 对外暴露的端口正确(端口要求见 8.5.1 使用要求)。
Verilog 语言实现:要求采用结构化设计方法,用 Verilog 语言实现处理器的设计。设计包括:
• 各模块的详细设计(包括各模块功能详述,设计方法,Verilog 语言实现等)
• 各模块的功能测试(每个模块作为一个部分,包括测试方案、测试过程和测试波形等)
• 系统的详细设计(包括系统功能详述,设计方法,Verilog 语言实现等)
• 系统的功能测试(包括系统整体功能的测试方案、测试过程和测试波形等)
对 Cache 进行仿真测试,记录运行过程和结果,完成实验报告。
五、设计思想
1、给出设计的指令Cache的状态转移自动机,解释各个状态,并简要说明Cache在hit和miss时都是如何进行工作的。

如果在hit了,则cache一直处于RUN状态,并且向cpu发出cache_data_ok=1信号,表示信号已经到达数据线上,cpu可以取数了;如果miss,则将从RUN状态跳转到SEL_WAY状态,在该状态进行选路,并根据 LRU 算法进行选路,为接下来 Cache 的替换和更新做准备。 Cache 每次只会在该状态停留一拍用于确定选路,然后自动跳转到MISS状态,缺失状态,更新 lru 表,并向主存储器发起读数据请求,即给 AXI 总线发送 arvalid = 1,同时发送数据地址,请求读取 Cache 中未命中的行,如果主存储器接收了读请求,即 AXI 总线返回 arready = 1,则 Cache 进入到数据重填状态接收返回的数据。REFILL状态, Cache 接收主存储器传回的数据,并根据选路状态给出的选路结果更新目录表和数据块,状态持续到数据传输完成,即 AXI 总线返回 rvalid = 1 && rlast = 1。FINISH状态,标志 Cache 更新完成, Cache 将在下一个时钟周期回到运行状态,重新进行上次未命中的访存。
2、解释你设计的指令Cache是如何实现二/四路组相联的,请简要说明实现的算法。
分别实现一路的目录表的和数据块,然后对于n路组相联,就实例化n个该模块,数据块设计如下:先实现缓存一路的数据块,输入信号包括时钟信号,使能信号(32位,哪一位为1,表示哪一位能被写入),索引,偏移量和写入数据,输出相应的读出数据。使用了ip核,对于1路数据,要使用8个ip核才能完成。

 目录表设计如下:和数据块的设计思路几乎一样,添加了一个tmp_hit信号,用来存上一个命中结果。
目录表设计如下:和数据块的设计思路几乎一样,添加了一个tmp_hit信号,用来存上一个命中结果。

六、代码实现
给出实现 Cache 的Verilog代码:
module cache(
input clk , // clock, 100MHz
input rst , // active low
// Sram-Like接口信号定义:
// 1. cpu_req 标识CPU向Cache发起访存请求的信号,当CPU需要从Cache读取数据时,该信号置为1
// 2. cpu_addr CPU需要读取的数据在存储器中的地址,即访存地址
// 3. cache_rdata 从Cache中读取的数据,由Cache向CPU返回
// 4. cache_addr_ok 标识Cache和CPU地址握手成功的信号,值为1表明Cache成功接收CPU发送的地址
// 5. cache_data_ok 标识Cache和CPU完成数据传送的信号,值为1表明CPU在本时钟周期内完成数据接收
input cpu_req , //由CPU发送至Cache
input [31:0] cpu_addr , //由CPU发送至Cache
output [31:0] cache_rdata , //由Cache返回给CPU
output cache_addr_ok, //由Cache返回给CPU
output cache_data_ok, //由Cache返回给CPU
// AXI接口信号定义:
// Cache与AXI的数据交换分为两个阶段:地址握手阶段和数据握手阶段
output [3 :0] arid , //Cache向主存发起读请求时使用的AXI信道的id号,设置为0即可
output [31:0] araddr , //Cache向主存发起读请求时所使用的地址
output arvalid, //Cache向主存发起读请求的请求信号
input arready, //读请求能否被接收的握手信号
input [3 :0] rid , //主存向Cache返回数据时使用的AXI信道的id号,设置为0即可
input [31:0] rdata , //主存向Cache返回的数据
input rlast , //是否是主存向Cache返回的最后一个数据
input rvalid , //主存向Cache返回数据时的数据有效信号
output rready //标识当前的Cache已经准备好可以接收主存返回的数据
);
//7种状态:
/*
IDLE 空转状态, Cache 恢复正常工作前的缓冲状态,会在下一个时钟周期转移到运行状态。
RUN 运行状态, Cache 不发生数据缺失正常两拍返回数据的状态。发生数据缺失,即目录表输出
hit = 0 时则,会进入选路状态开始进行 Cache 的替换和更新。
SEL_WAY 选路状态,如果 Cache 发生数据缺失,就会进入这一状态,并根据 LRU 算法进行选路,为接
下来 Cache 的替换和更新做准备。 Cache 每次只会在该状态停留一拍用于确定选路,然后自
动跳转到缺失状态。
MISS 缺失状态,更新 lru 表,并向主存储器发起读数据请求,即给 AXI 总线发送 arvalid = 1,
同时发送数据地址,请求读取 Cache 中未命中的行,如果主存储器接收了读请求,即 AXI 总
线返回 arready = 1,则 Cache 进入到数据重填状态接收返回的数据。
REFILL 数据重填状态, Cache 接收主存储器传回的数据,并根据选路状态给出的选路结果更新目录
表和数据块,状态持续到数据传输完成,即 AXI 总线返回 rvalid = 1 && rlast = 1。
FINISH 重填完成状态,标志 Cache 更新完成, Cache 将在下一个时钟周期回到运行状态,重新进行
上次未命中的访存。
RESETN 初始化状态,当用于处理器初始化时清空 cache,持续 128 个时钟周期,每个周期清空一行。
*/
parameter IDLE = 0;
parameter RUN = 1;
parameter SEL_WAY = 2;
parameter MISS = 3;
parameter REFILL = 4;
parameter FINISH = 5;
parameter RESETN = 6;
reg [2:0] state; //存自动机的状态
reg [6:0] counter;//计数器0-127共128个数
wire hit;//存命中结果
wire hit_way;//命中的路
wire tmp_hit;
//地址流水段 request_buffer
wire [31:0] current_addr;
wire [19:0] current_tag;
wire [6:0] current_index;
wire [4:0] current_offset;
assign current_addr = cpu_addr;
assign current_tag = cpu_addr[31:12];
assign current_index = cpu_addr[11:5];
assign current_offset = cpu_addr[4:0];
reg last_req ;
reg [31:0] last_addr;
reg [19:0] last_tag ;
reg [6 :0] last_index ;
reg [4 :0] last_offset ;
reg [31:0] ll_address;//上上个指令地址
reg [19:0] ll_tag;
reg [6:0] ll_index;
reg [4:0] ll_offset;
always @(posedge clk) begin
if (!rst) begin
last_req <= 0;
last_addr <= 0;
last_tag <= 0;
last_index <= 0;
last_offset <= 0;
ll_address <= 0;
ll_tag <= 0;
ll_index <= 0;
ll_offset <= 0;
end
else if (cpu_req & (state == RUN)) begin //!!!!!
last_req <= cpu_req;
last_addr <= current_addr;
last_tag <= current_tag;
last_index <= current_index;
last_offset <= current_offset;
ll_address <= last_addr;
ll_tag <= last_tag;
ll_index <= last_index;
ll_offset <= last_offset;
end
else begin
end
end
//控制模块:LRU模块 + 状态自动机模块
//控制模块之状态自动机模块
always @(posedge clk) begin
if (!rst) begin//重置信号为0,状态设置为RESETN ,说明需要初始化
state <= RESETN ;
end
else begin
/*TODO:根据设计的自动机的状态转移规则进行实现*/
case(state)
IDLE : state <= RUN;//一个节拍后,自动跳转
RUN : state <= (last_req && !tmp_hit)? SEL_WAY : RUN;
SEL_WAY :state <= MISS;
MISS : state <= (arready == 1)? REFILL: MISS;
REFILL: state <= (rlast == 1)? FINISH :REFILL;
FINISH : state <= RUN;
RESETN : state <= (counter == 127 )? IDLE : RESETN ;//如果满128拍,则跳转到下一个状态IDLE
default : state <= IDLE;
endcase
end
end
assign cache_addr_ok = (cpu_req == 1 )&& (state == RUN);
//控制模块之LRU模块
//该模块分为两部分:
//(1)LRU选路,当处于SEL_WAY时进行选路,一个节拍输出结果
//(2)LRU更新,根据选路结果进行LRU表更新,一个节拍完成,该节拍被我安排在了SEL_WAY节拍紧接着的下一个节拍,也就是MISS状态
//注意:MISS状态可能持续好几个节拍,AXI总线返回来的aaready是否为1,为1则在下一个节拍变成REFILL状态
//lru表
reg [127:0] lru;//由于两路,lru表设计为128行*1列,第n列为0表示第0列用的少,选择第0列
reg [1:0] selway;//选路的结果,01表示选择第0路,10表示选择第1路
// 根据自己设计自行增删寄存器
//(1)LRU选路
always@(posedge clk) begin
if(!rst) begin
selway <= 0;
//lru <= 0;
end
else if(state == SEL_WAY)begin
case(lru[ll_index])
1'b0: selway <= 2'b01;
1'b1: selway <= 2'b10;
default:;
endcase
end
else begin
end
end
//(2)lru表更新(一拍就够,但是持续整个MISS状态好像也没影响):两种情况:RUN命中/MISS不命中
always@(posedge clk) begin
if(!rst) begin//重置时,将lru表清空,即都选择第0路
lru <= 0;
end
else if(state == MISS)begin//MISS不命中
case(selway)
2'b01: lru[ll_index] <= 1'b1;//如果选路结果为01,说明选择第0路进行使用,那么第1路就将变为最近最少使用
2'b10: lru[ll_index] <= 1'b0;
default:;
endcase
end
else if(state == RUN && hit == 1)begin//RUN命中
lru[ll_index] = ~hit_way;//hit_way是命中的路
end
else begin
end
end
// RESETN状态:从state = RESETN开始从0计数,每一拍加一,当记满128拍后说明初始化完成
initial begin
counter <= 7'b0;
end
always@(posedge clk) begin
if(!rst) begin
counter <= 7'b0;//计算器清零
end
else if(state == RESETN) begin//如果为RESETN 状态,则计数器加1
counter <= counter + 7'b1;
end
else begin
end
end
//refill模块
reg [2:0] refill_counter;//记录当前refill的指令个数
always@(posedge clk) begin
if(!rst) begin
refill_counter <= 0;
end
else if(state == REFILL && rvalid) begin
refill_counter <= refill_counter + 1;
end
else begin
end
end
//目录表和数据块
//目录表
//tagv_wen:目录表写使能,第n位代表第n路写使能(高有效),一下两钟情况改变使能信号可能为1,其余都为0。
// RESETN状态时,赋值为11,进行初始化;
// cache不命中时,根据LRU的结果selway进行赋值,
// selway为01,表示选择第0路更新,写使能赋值01,表示第0路目录表可以被更新(可认为等于selway)
//tagv_index:作为目录表索引,进行查找,同时用于两个目录表
// RESETN状态时,在128拍中,index从0变成127(可认为等于counter)
// RUN状态时,为cpu输出,地址流水段输出last_index
// 其他状态为ll_index
//tagv_tag:标识
// RUN状态时,为地址流水段输出last_tag
// 其他状态为ll_tag
//valid_wdata:写入有效位的值
// RESETN 时为0,其他情况为1
//hit_array :命中结果,第n路为1,表示第n路命中(n等于2)
wire [1 :0] tagv_wen;
wire [6 :0] tagv_index;
wire [19:0] tagv_tag;
wire [31:0] valid_wdata;
wire [1:0] hit_array;
wire [1:0] tmp_hit_array;
assign tagv_wen[0] = (state == RESETN || (state == MISS && selway[0] == 1))? 1:0;
assign tagv_wen[1] = (state == RESETN || (state == MISS && selway[1] == 1))? 1:0;
assign tagv_index = (state == RESETN ) ? counter : ((state == RUN)?last_index : ll_index);
assign tagv_tag = (state == RUN) ? last_tag:ll_tag;
assign valid_wdata = (state == RESETN )? 0:1;
//数据块(写情况:不命中时候需要更新数据块)
wire [31 :0] data_wen [1:0];
wire [6 :0] data_index;
wire [4 :0] data_offset;
wire [255:0] data_wdata;
wire [31 :0] data_rdata [1:0];
wire [4:0] refill_wen;
assign refill_wen = refill_counter << 2;//记录需要右移的位数
assign data_wen[0] = ((selway[0] == 1 && rvalid && state == REFILL)) ? (32'hf0000000 >> refill_wen):0 ;
assign data_wen[1] = ((selway[1] == 1 && rvalid && state == REFILL)) ? (32'hf0000000 >> refill_wen):0 ;
assign data_index = (state == RUN)? last_index : ll_index;
assign data_offset = (state == RUN)? last_offset : ll_offset;
assign data_wdata = {8{rdata}} ;
generate
genvar j;
for (j = 0 ; j < 2 ; j = j + 1) begin
icache_tagv Cache_TagV (
.clk (clk ),
.wen (tagv_wen[j] ),
.index (tagv_index ),
.tag (tagv_tag ),
.valid_wdata(valid_wdata ),
.hit (hit_array[j]),
.tmp_hit(tmp_hit_array[j])
);
icache_data Cache_Data (
.clk (clk ),
.wen (data_wen[j] ),
.index (data_index ),
.offset (data_offset ),
.wdata (data_wdata ),
.rdata (data_rdata[j])
);
end
endgenerate
assign hit = (hit_array[0] || hit_array[1]) && (state == RUN);
assign tmp_hit=(tmp_hit_array[0] | tmp_hit_array[1]) & (state==RUN);
assign hit_way = (hit_array[0] == 1)? 0 : 1;//命中的是哪一路
/*------------ CPU<->Cache -------------*/
//cache_addr_ok
assign cache_data_ok = last_req && hit;
assign cache_rdata = data_rdata[hit_way];
/*-----------------Cache->AXI------------------*/
// Read
assign arid = 4'd0;
assign arvalid = (state == MISS)?1:0;
assign araddr = ll_address & 32'hffffffe0;
assign rready = (state == REFILL)?1:0;
endmodule
七、测试结果及实验分析
测试结果:
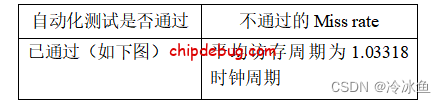

这个测试pass的总时长为4241475ns,一共有410527次访存,平均每个访存耗费1.03318时钟周期。
八、实验总结
这次实验要求实现一个指令cache,通过实际操作,更加熟悉了组相联cache的工作原理(包括目录表和数据块),以及cache和CPU、主存之间的数据交换方式,例如cache时通过发送给CPU的cache_addr_ok和cache_data_ok信号来告知CPU当前cache的状态。总之,这次实验十分有趣,也使我更加熟悉了cache的工作原理,收获颇丰。
九、源代码
没有回复内容