

发表于 2020 TPAMI,原文标题:learning image-adaptive 3d lookup tables for high performance photo enhancement in real-time
目前广泛使用的图像色彩调整都是基于 LUT 来做的,而 LUT 图是由人工设计的,这篇文章结合了 CNN 和 LUT,能够根据图片内容调整 LUT 图从而获得更好的增强效果,并且运行速度很快。
不熟悉 LUT 的可以戳这里看看
https://www.zhangxinxu.com/wordpress/2020/02/3d-lut-principle/
创新点和局限
创新点:
- 论文结合了 CNN 和 LUT,能够根据图片内容自动调整LUT图获得更好增强效果
- 速度很快,模型只有 600K 参数,计算量在 70M,在 NVIDIA Titan 显卡上只需要2ms就可以处理完一帧,实测在大部分中高端手机上也是可以实时运行的。
局限
- 局部增强效果不佳,文中结合了 local tone mapping 来做优化
方法架构
该方法的运行流程图如下
色彩增强的核心环节中,图片增强是由几个基础的 3DLUT 联合完成的,作者在这里设计了一个小的 CNN 网络,用来给这几个 LUT 图赋予权重,从而达到图片内容自适应的目的。 公式如下:
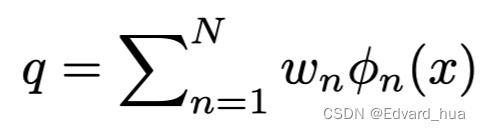
其中 n 表示 LUT 图的个数,w 表示网络预测出来的权重,Φ 表示增强操作。
具体的,论文中使用了3个 3DLUT 来对图片进行内容自适应增强
预测权重的网络架构如下图所示:

其实就只有5层卷积,1 层 dropout 和 1 层全连接,使用了 Leaky-ReLU 和 instance-normalization,我使用 torchprofile 测试了一下,计算量在 70M,是计算量很小的一个网络,甚至在手机上也是可以实时运行。
训练细节
训练这个环节里,比较大的改动是在损失函数计算这里,加入了两个正则化的约束。

由三块构成,第一块是 MSE,第二块 Rs 是平滑正则化,第三块 Rm 单调正则化,由两个 λ 参数控制着。
Total Variation (TV) 平滑正则化
加入了 TV(Total Variation)平滑正则化,用于稳定转换输入的图像到指定的色彩空间。

TV 是图像恢复中常见平滑正则化技术,常用于分割,降噪等算法,用于保持输出结果的光滑性。
参考文献:https://blog.csdn.net/yexiaogu1104/article/details/88395475
单调性正则化
论文设计了一个单调性正则化来约束 3D Lut 的训练,它有如下两个优点
- 它能够让增强后的图片,饱和度和亮度过渡更加的自然
- 训练数据可能不足以覆盖整个颜色空间,有助于更新无法被输入 RGB 值激活的参数,提高泛化能力

其中,g 表示 ReLU 激活函数,c_o 表示输出 RGB 值,这个正则化主要是保证输出的 RGB 值是随着 3D Lut 的下标 i,j,k 递增而递增的。
正则化参数 λ 的选择
为了选取合适的参数,这里做了一系列的实验。
TV 参数 λ 的范围在 { 0, 0.00001, 0.0001, 0.001, 0.01, 0.1 },而单调性参数 λ 的范围在 { 0.1, 0, 1.0, 10, 100, 1000 },为了确定最佳参数的选择,画出 PSNR 值随 λ 值变化的曲线图
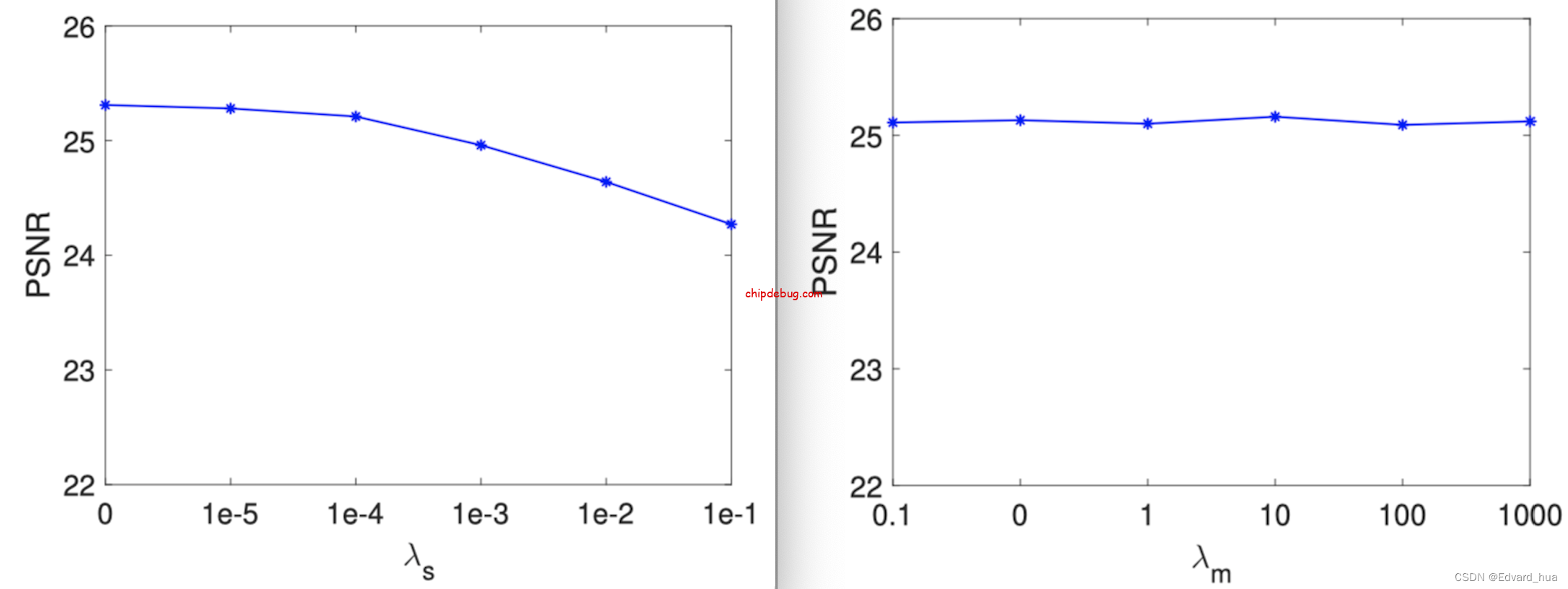
从图中可以看出,TV 参数 λ 在大于 0.0001 后会导致 PSNR 值的下降,过大的值会导致过渡平滑的结果,从而限制了泛化性。在单调性这里我们发现它对权重 λ 的变化并不敏感,可能是因为单调性是 3DLut 天然特征导致的,那我理解其实这个单调性正则化或许不加入进去也不会影响模型的最终结果吧。= =
文章还对 3D Lut 图做了一系列骚气的可视化,感兴趣的可以去看原文
具体的,这两个正则项的计算在代码中打包成了一个 module 在 models.py 源码文件中。
class TV_3D(nn.Module): def __init__(self, dim=33): super(TV_3D, self).__init__() self.weight_r = torch.ones(3, dim, dim, dim - 1, dtype=torch.float) self.weight_r[:, :, :, (0, dim - 2)] *= 2.0 self.weight_g = torch.ones(3, dim, dim - 1, dim, dtype=torch.float) self.weight_g[:, :, (0, dim - 2), :] *= 2.0 self.weight_b = torch.ones(3, dim - 1, dim, dim, dtype=torch.float) self.weight_b[:, (0, dim - 2), :, :] *= 2.0 self.relu = torch.nn.ReLU() def forward(self, LUT): dif_r = LUT.LUT[:, :, :, :-1] - LUT.LUT[:, :, :, 1:] dif_g = LUT.LUT[:, :, :-1, :] - LUT.LUT[:, :, 1:, :] dif_b = LUT.LUT[:, :-1, :, :] - LUT.LUT[:, 1:, :, :] tv = torch.mean(torch.mul((dif_r ** 2), self.weight_r)) + torch.mean( torch.mul((dif_g ** 2), self.weight_g)) + torch.mean(torch.mul((dif_b ** 2), self.weight_b)) mn = torch.mean(self.relu(dif_r)) + torch.mean(self.relu(dif_g)) + torch.mean(self.relu(dif_b)) return tv, mn 数据集
MIT-Adobe FiveK dataset: https://data.csail.mit.edu/graphics/fivek
相机拍摄了 5000 张 RAW 格式的图片,然后聘请了五位艺术生对这些照片进行调色,以获得图片最佳的观赏效果。
Google HDR+ Burst Photography Dataset: https://hdrplusdata.org
谷歌的 Pixel 相机拍摄了 3640 张图片,然后再用谷歌的 hdr+ 算法对这些图片进行处理得到色彩增强后的图像。
效果评估
指标: PSNR 和 SSIM,还有一个 delta E,色彩增强任务的效果评估其实蛮主观的,文中出现了大量的对比图
论文对比了两个技术流派下,SOTA 模型的效果
配对训练 SOTA 模型对比,HDRNet,DPE,Dis-Rec, UPE

从对比图可以看到,UPE 的结果在饱和度和对比度上都不足,Dis-Rec 不够鲁棒,存在过曝和颜色不自然的问题,而 DPE 则会出现光晕的问题,能与本论文方法相媲美的就只有 HDRNet 了,为了分个高低,论文中进一步对比了 HDRNet,如下图所示:

这里可以看到 HDRNet 出来的图,在天空这里颜色已经出现了问题,泛紫了,猜测出现这种现象是因为 HDRNet 的训练数据集中大部分的天空不是红色就是蓝色,从而过拟合了。
非配对训练 SOTA 模型的比较,这里除了对了 Pix2Pix 和 CycleGAN 等算法之外,还对比了 Photoshop Camera Raw 中的自动增强功能,指标如下表所示
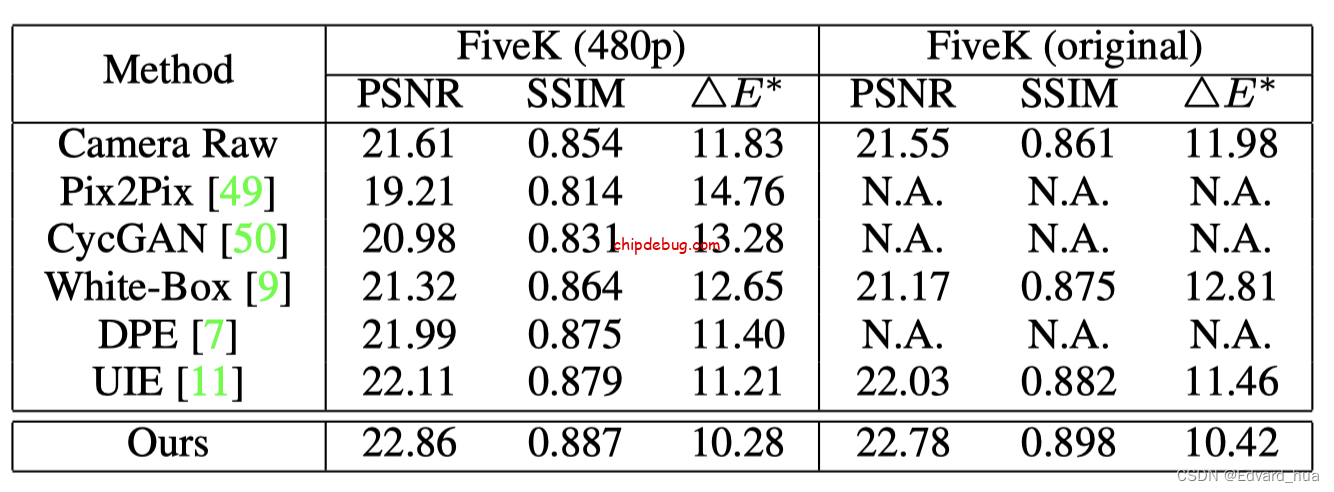
从表中可以看出,他们的方法在三项指标上都比次好的 UIE 方法分别要高,另外一个有意思的事情是 Camera Raw 的自动增强功能在没有利用 FiveK 数据集的情况下,指标比大部分用了该数据集训练的模型在指标上都要好上不少,Adobe 屌中屌。

但从主观的图片对比来看,非配对的方法表现上是不够稳定的,从上图的对比中我们可以看到,Pix2Pix 和 CycleGAN 方法出来的图其实有存在明显的人工痕迹 Artificial,在颜色表现不自然,图像内容也有轻微的扭曲
论文还对比了相机 pipeline 下的处理效果,感兴趣的可以去看下原文,这里不展开。
计算量,运行速度
在 Nvidia Titan RTX 测试得到的运行速度如下表所示
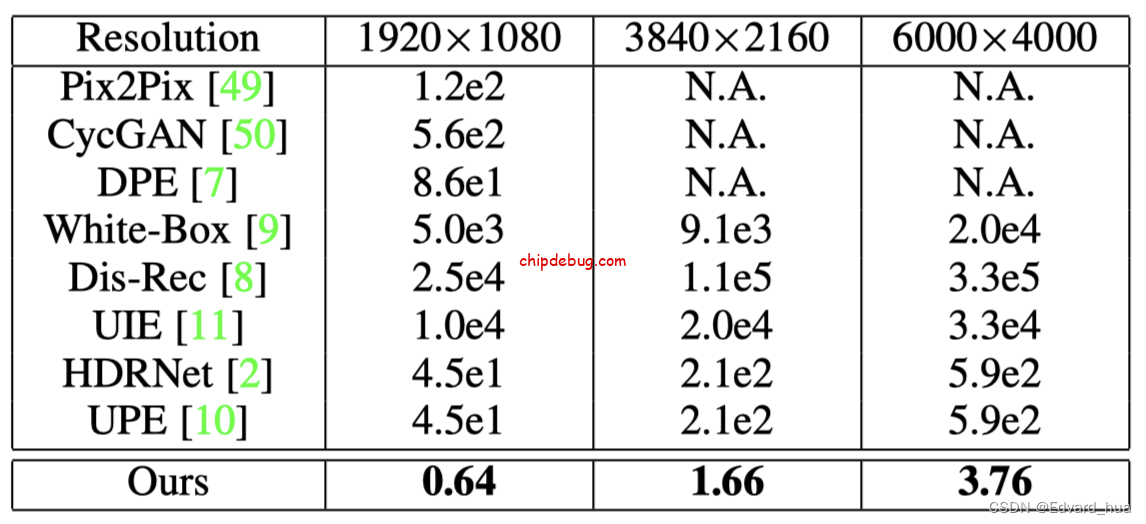
我尝试了在 iPhone 6s 上,以 256×256 作为输入,预测一帧速度在 1ms 左右,能够达到落地的效果。
当前方法的限制主要还是在于无法针对局部区域进行增强,论文这里用了 local tone mapping 的方法来优化这个问题并给了一个示例对比图。

参考文献
Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time
https://arxiv.org/abs/2009.14468
没有回复内容